
在自己的电脑上做文档扫描
Tue Sep 23 2025 08:00:00 GMT+0800 (China Standard Time)
1.为什么要在自己电脑上做OCR
最近有些手写资料要记录成电子版,于是拍照后想做ocr识别,但是因为有些机密,不能上传到第三方服务器。 因此需要在自己的电脑上创建能进行OCR的服务,这样既不用上传照片,又不用手动输入, 只需要在自建服务识别后,进行一次检验复制就可以了。
2.搭建自用OCR服务的过程
2.1 找个计算平台软件
为了不上传到第三方服务器,那么就需要自己有服务器,要是租云平台的服务器又需要一部分成本,
因此要把自己的PC改成服务器,那么如何将自己的PC改造成计算平台呢?
这里有个开源软件llama.cpp,
可以在PC上实现大模型推理需要的线性计算,更重要的是,llama.cpp广泛支持各种GPU或计算库,
就算没有GPU,通过CPU也能进行大模型推理。

2.2 找个性能平衡的模型库
找到计算平台llama.cpp后,需要到huggingface上找一个能在llama.cpp上运行的模型库,
既能快速计算,又能精确识别大部分内容。Nanonets-OCR-s-GGUF
是找到的性能满足需求的库,其经过量化Q4_K_M就能很好地完成任务。
2.3 结合llama.cpp和Nanonets-OCR-s-GGUF
llama.cpp可以直接下载已经编译好的对应可执行文件,但是如果从源码编译的话,能更好地发挥PC的性能, 更重要的是也非常简单:
2.3.1.下载源码:git clone https://github.com/ggerganov/llama.cpp.git
2.3.2.进入源码根目录并生成编译文件: cd llama.cpp && cmake -B build
2.3.3.编译llama-server: cmake —build build -j —target llama-server
2.3.4.运行: ./build/bin/llama-server -hf unsloth/Nanonets-OCR-s-GGUF:Q4_K_M
3.还有哪些不足
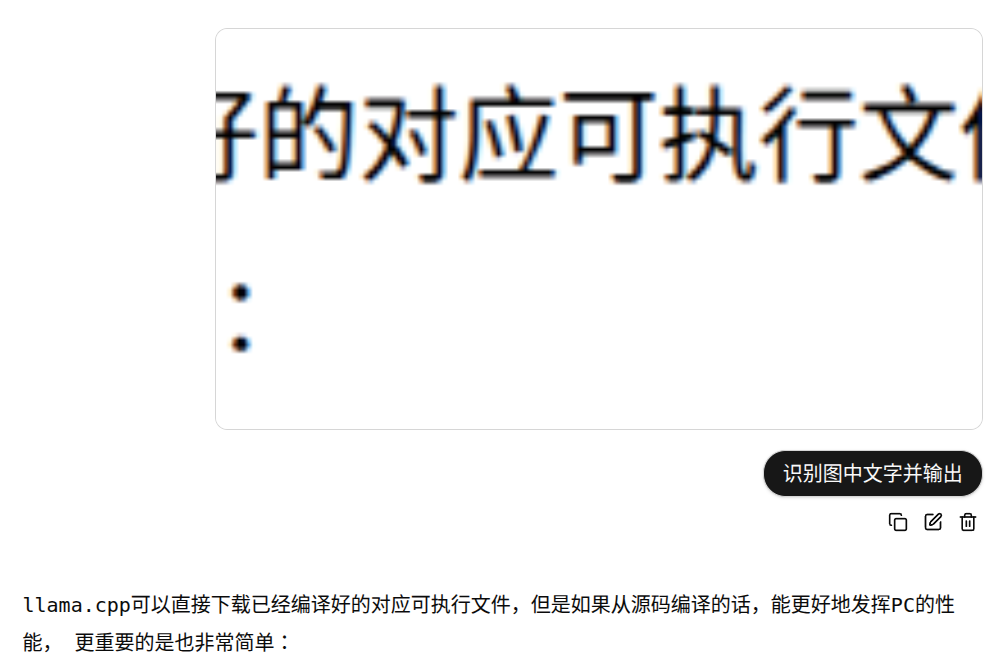
例子是将本文的一部分截图后,识别其中的文字出来。运行速度没有想象的快,但是如果将图片进行缩小后速度会快很多。 因需求都是识别文字,因此没有完全发挥出Nanonets-ocr-s库的性能, 如果您有更多的需求,可以看看其说明。
llama.cpp和Nanonets-ocr-s都需要科学上网才能下载,如果您只是下载很少的资源,同时不需要长时间科学上网, 那么这个服务您可以看看。